RD Controls<P>
EPICURE Software Release Note 91.0<P>
<b> WARNER Cluster</b><P>
<b> Power Recovery Reboot Procedure</b>
RD Controls
EPICURE Software Release Note 91.0
WARNER Cluster
Power Recovery Reboot Procedure
Deb Baddorf
The desired general plan for WARNER power-recovery reboots is that all nodes
will automatically reboot when the power returns, with no user intervention.
However, this scheme has problems, at the present, in that all the nodes
contend for the same files and the same batch queues, and bottlenecking
occurs, causing up to 3 hour reboot times for the entire cluster.
In fact, the bottlenecking is such that many workstation nodes will
not manage to reboot by themselves, but will either give up after many
tries, or will get stuck in the middle of the reboot.
Until this problem is resolved, the following manual intervention
procedure will suffice to reboot WARNER in a faster manner, allowing
logins after less than half an hour on selected nodes. The remaining nodes
will be rebooted manually at spaced intervals until the whole cluster
is online.
The Setup
The core nodes are set to boot automatically on power up:
- DAFFY
- ELMER
- CHIP
- DALE
- BASIL
- THYME
The last four above are workstations, and may get tired of ``retrying''
and thus timeout before DAFFY and ELMER are capable of
booting them. If this happens, look for the ``>>>'' console prompt
via the ARDYH console monitor program
and type ``B'' or ``BOOT'' (no quote marks).
CHIP may take half an hour longer to boot, but will probably
get there eventually. CHIP has a tape in its MUA0 drive.
Therefore, it defaults to searching the entire tape for a system boot
file (it isn't there) before getting around to asking for a boot
over the network. Newer type nodes can be programmed to look directly
at the ethernet, and skip local disks and tapes, but the MicroVAX II's
cannot.
The other nodes (currently there are 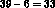 other nodes) will
power up, perform self tests, and try to reboot too. Many will time out
and fail (VS2000's don't have much patience); some may get half way and
fail due to contention; some may succeed. Unfortunately, since they
have to wait till the core nodes are far enough along to provide the
needed data, the ``timeout and stop trying'' mode is the most common.
other nodes) will
power up, perform self tests, and try to reboot too. Many will time out
and fail (VS2000's don't have much patience); some may get half way and
fail due to contention; some may succeed. Unfortunately, since they
have to wait till the core nodes are far enough along to provide the
needed data, the ``timeout and stop trying'' mode is the most common.
While Power Is Out
If the opportunity is available, the cluster will recover more
cleanly (my opinion) if you walk around to all non-core nodes and power them
off while the power outage is underway. This way you can wait till the
core nodes have successfully rebooted, and then power up 4-6 workstation
nodes at a time, allowing 20-30 minutes between batches.
Power Returns
After power is restored, watch the monitor terminal attached to ARDYH
in the computer room. When this terminal has a grey window background
(and not before) use the mouse to create a window, and log in to
account VCSMONITOR.
It will log in, and start the VCS program, monitoring the WARNER
core nodes.
At this point you should be able to log into DAFFY or ELMER too, using
a terminal on the terminal server. This is because these are faster
rebooting nodes and will already be up by the time ARDYH is up.
NOTE: If for some reason ARDYH is dead and will not boot, estimate 20
minutes from power up and then try to log in to DAFFY and ELMER
from the terminal server. Otherwise, if ARDYH is okay,
the reboot time for ARDYH serves
as a good estimate for DAFFY and ELMER having time to finish
the basic reboot as well as the startup of EPICURE processes.
Booting The Other Nodes
When To Boot The Other Nodes
Suggested time delay: I suggest you boot another bunch of 4-5 nodes every
20-30 minutes.
Order To Boot Other Nodes
Get a list of the remainder of WARNER nodes from Deb's office on
WH12W. It'll be on a magnet attached to a file cabinet.
The list will not be included in this document, as it changes
too often to be updated here. The list is sorted by physical location,
so you can find them better.
How To Boot These Other Nodes
- Core nodes:
- (These are the 6 listed at the beginning of this document.)
These should be up as covered in the above section, but try to SET HOST
to them to be sure they all
made it. If you cannot log in to one of the core nodes,
go to the ARDYH workstation monitor. Log in using the account name VCSMONITOR.
Once logged in, the cursor
will be at the bottom of the screen ( not inside the windowed area),
and the prompt
will be the word ``Command:''. Type
Command: VIEW nodename
If the display shows that the node is waiting at the >>> prompt, then
perform the following steps to boot it. If the display shows activity
on the node, it is probably in the process of booting; leave it alone.
To tell the node to boot:
Command: OUTPUT nodename BOOT !for most nodes
Command: OUTPUT nodename BOOT XQ !for CHIP or DALE
Use the name of the node you want to boot in place of the word nodename
and press carriage return at the end of the line.
This should be all you need to know about VCS for rebooting, but
more information about using the VCS monitor program is available in
EPICURE Software Release Note 14.
If ARDYH is not available, call the system manager (see call-in list).
You will need to do the following (with telephone prompting) for each
node:
- Throw a switch in the back of the node.
- Press the RESTART button on the front of the node.
- After 5 minutes, return the switch in the back to the original
position.
- Workstations:
- I suggest doing 4-5 nodes at a time, and
waiting 20-30 minutes before doing another batch.
If you have gone around and switched them all
off, then reboot them by switching them on. They should continue
by themselves (unless too many nodes are booting and they time out
waiting for a response).
If they were not powered off, or if they have timed out and given up
trying, the main screen should have a >>> prompt symbol.
If there is no >>> prompt, hit the tiny recessed HALT button
to get the prompt.
At the prompt, type B
or BOOT and then carriage-return. Workstation nodes do not use
ARDYH; their prompts go to the main workstation screen itself.
Walk around and check all nodes again when you think they are all up.
Make sure you can pop up a login box (the box with the ``Create Window''
choices) on each node. You don't need to actually log in. If some nodes
have gotten in a strange mode, they will look like the window system is
up, but they won't let you pop up a login box. Nodes CHLDRS (Childress),
WRNLS (Stutte), and WRNGRG (Gutierrez) are particularly
susceptible to this failure mode.
A node which is in this state must be rebooted again.
If you are in the controls group (Watts' and Larwill's people)
the preferred method to reboot these nodes is: log in on another node,
as yourself. SET HOST to the troubled node; log in as SHUTDOWN.
Choose the REBOOT option, answer any questions, and let it proceed.
Other people will have to use the brute force methods: hit the recessed
HALT button and type B, or power cycle the node if you can't find
the button.
Keywords: EPICURE, WARNER, computer, reboot, power fail
Distribution:
normal
RD Site Operations
Security, Privacy, Legal
rwest@fsus04.fnal.gov