Research Division EED/Controls Software<P>
Release Note 152.0<P>
The Collection and Logging of Device Data
Research Division EED/Controls Software
Release Note 152.0
The Collection and Logging of Device Data
Robert E. West
Septermber 21, 1995
Introduction
The EPICURE Data Logging System consists of three parts:
- Specification of the devices from which data is to be collected
- Collection of the specified data and writing of the data to disk
- Extraction and plotting of the recorded data
This document describes the second part, the EPICURE data logging utility for
collecting and recording of the data.
Operation
Network Interface
When the data collection process starts, it declares itself to be a network
object so that it may receive commands over the network from other processes.
This interface is used by the data logging editor process to restart a data
acquisition list after a user has made modifications to the devices on the
list. The command RESTART followed by a list number from 1 to 6 tells the
collection process to read the specified list's file of device names and then
rebuild the data acquisition list. Other network commands exist for system
and diagnostic purposes.
In addition to writing to disk the data it has collected, the collection
process may receive data records over the network from other collection
processes and then write these records into its file of collected data.
In most cases, if the process is functioning as a file server, it probably
would not also be collecting data. Both functions may be performed by the
same process, but the workloads must be balanced to avoid losing data.
Data Acquisition
The data collection process of the EPICURE logging system is configured to
execute
six data acquisition lists each having a maximum of 180 devices. If the
reading, setting, and status properties of each device are to be logged, a
maximum of 540 items may be on a single list.
Tuning parameters may be used to further limit the number of items allowed on
each list. These limit parameters,
along with other control parameters, are read from a file on disk.
The times and/or rates at which the data acquisition
lists collect data are also specified by control parameters read from disk.
The device names and properties to be read by a data acquisition list are
contained in a text file on disk. There a six of these device files, one for
each
of the six possible data acquisition lists. When the data collection process
starts, it reads each of these files and creates the corresponding data
acquisition lists. The data logging editor process is used to modify the
contents of these device files and then to tell the data collection process
to read the new file and rebuild the corresponding data acquisition list.
A memory buffer is allocated for the data collected for each item on a
data acquisition list. A memory buffer contains 120 data points.
A data point consists of the timestamp of the device access and the data value
converted to engineering units in floating point format.
When the buffer is full, it is queued to be written to disk and another buffer
is allocated.
If the time between reads of a device is once a minute, the
buffer is written to disk after two hours. The longer the time between the
device reads, the longer it takes for the buffer to fill and the more data
that would be lost if the system crashed. The buffer may be flushed
to disk after the insertion of a specific number of data points. Because
the data
acquisition lists may be executed at different rates, each list has its own
flush count parameter.
The data collection process fills a device buffer with the data as it is read.
This operation takes place at the AST interrupt level
of processing. When the buffer is full, it is queued to be written to disk
at the base level of processing. If the buffers can't be written to disk fast
enough relative to the rate at which data is being read, then eventually the
process is going to run out of data buffers.
When this occurs, the interrupt processing of data input is disabled until an
adequate number of buffers have been output to disk and are then
available for new data. The result of this overload is a `hole' in the
logged data of all the devices, i.e., a period of time during which no data
has been collected and recorded.
Output to Disk
The EPICURE data logging system is designed to provide circular logging.
The duration of
a data acquisition list's data is how long before old data is
overwritten with new data. This time period is a function of (1) the rate at
which data is collected by the list, (2) how many items are being read by the
list, and (3) how many disk records the list is allowed to have.
The data collected from all six data acquisition lists is written into the
same disk file. This file is organized as an indexed sequential file with
two keys.
The alternate key is the device name followed by the first timestamp
in the buffer. The alternate key may have one or more duplicates and
changes each time a particular
record in the file is overwritten with a full buffer of new data.
The primary key is the number of the data acquisition list (1 to 6)
followed by the record number for this list. The record number starts with
1 and increments until it is greater than the maximum allowed for the particular
list, at which time it is reset to 1.
Control parameters specify the maximum number of records for each list.
The primary key is unique.
Once a particular record is written to the logging file, its primary key never
changes.
The purpose of the primary key is to quickly locate and then overwrite
an earlier data record. Outputting a device
buffer to disk consists of finding the record having the primary key
contained in the buffer and then updating that record with the new data.
When the data collection starts execution, it reads a disk file to determine
where records were last written into the file of collected data.
This is done so that new data will be written at the correct position in the
file, overwriting the oldest data collected by each list. The process
periodically updates this file with the reference number of the record last
written for each data acquisition list.
Performance
A data buffer contains 120 points. The time required to fill the buffer is
120 multiplied by the time between the acquisition of each data point. An RMS
record consists of a single buffer. If there are N items in a data
acquisition which is being executed every S seconds, then N records must be
output to disk every (120 * S) seconds, Otherwise, some collected data
will not be written to the disk file. A maximum of six data acquisition lists
may be executed, so the total number of records output per second is
specified by the following:
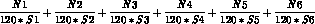
If each list contains the same maximum number N, then this expression
of the number of records output per second may be simplified to the following:
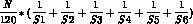
The number of seconds to output a single record is specified by the following:
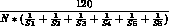
Writing a record to the file requires two RMS accesses, a FIND and then an
UPDATE. The number of seconds per RMS access is expressed by the following:
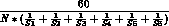
If the execution rates for the six lists are one second through six seconds
and each list contains 360 items, then each RMS access must be completed
within 68 milliseconds.
The data collection process calculates various measurements of its
performance. One of these statistics is the average time required for an RMS
access to the file. This time is dependent upon the speed of the VAX CPU,
the physical amount of memory, and the amount of other activity on the system.
An average RMS access time of as low as 50 milliseconds has been observed.
Writing a record to the file requires a FIND operation and then an UPDATE
operation. If the RMS access time is 50 milliseconds,
then the minimum time required to write a record is 100 milliseconds.
If no intermediate flushing of buffers is being done, 10 records containing
120 data points each, or a total of 1200 data points, can be output to disk
each second. If the reading of all the requested properties of all the
devices on all six of the collection process's data acquisition lists is less
than or equal to 1200 data points per
second, the data collection process probably will be able to write to disk
all the collected data. Counts higher than 1200 may result in some
collected data occasionally not being recorded.
Input Files
Execution Parameters
The logical name DLG_PARAMS_`node' specifies the file containing the
specifications of (1) the file into which the collected data is to be written
and (2) the various data acquisition lists which are to be executed. `Node'
is the name of the VAX node on which the data collection process is executing.
It is anticipated that only a single data collection processes will execute on
any one node. However, multiple collection processes are possible
if all the necessary logical names are correctly defined.
The parameter file is an ASCII text file which is read when the data collection
process starts its execution. A network input may be given to the collection
process to read this file anytime after the initial read. However, this would
only be necessary if a new version of the file was created using a text editor.
Each of the six data acquisition lists has its own set of parameters. The
format is the list number (1 to 6) followed by the parameter name followed by
the parameter value or values. The file contains the following information
for each data acquisition list:
- FTD - Frequency Time Descriptor specifying when data is
collected by the list. The format is interval, followed by event number,
followed by event type. If no event number or type is specified, the list
is created using the specified interval as the periodic rate. The list is
synchronized to the Tevatron clock if TEV is specified for the event type.
Otherwise, the list is synchronized to the phase reversal clock.
- MAX_ITEMS - The maximum number of items that may be in the list.
This is the total number of reading, setting, and status properties that can
be read, not the number of device names.
- FLUSH_COUNT - The number of new data points inserted into the buffer
after which the buffer will be written to disk.
The flush count is less than or equal to 120, the maximum number of
data points a buffer can contain. This
parameter results in a partially filled buffer being written to disk to
minimize the amount of data which may be lost in case of a system crash.
- MAX_BLOCKS - The number of records which may be written to disk for
this particular
data acquisition list. This parameter specifies the circular nature of the
data file. When this limit is reached, the record number for this list
is reset to one and this list's record with that record number in its primary
key is overwritten. If this value is too large, records will never be
overwritten and eventually disk space will be exhausted.
The text file may also contain the following optional parameters:
- FILE_OUTPUT - If this parameter is set to 1, the collection process
writes the collected data into the associated disk file. This is the default
case.
- NETWORK_OUTPUT - If this parameter is set to 1, the collection process
writes the collected data to a data logging file server.
The logical name DLG_SERVER_`node' specifies the node on which the file
server is executing and the
logical name DLG_SRV_OBJ_`node' specifies the server's network object name.
`Node' is the name of the VAX node on which the data collection process is
executing. Though possible, output to a file server is not expected to be
done if the collection process is writing the data to its own disk file.
- FILE_SERVER - If this parameter is set to 1, the data logging process
functions as a file server. It will not execute any data acquisition lists.
It only receives records of collected data from data logging processes and
then writes them into the logging file. The process could be configured
to serve both as file server and a collector of data, but it is not
anticipated that will be necessary.
- CIRCULAR - The file of collected data is normally treated as a circular
file which
sooner or later overwrites itself. This default case is indicated by this
parameter having a value of 1. If the parameter has a value of 0,
when one of the data acquisition sections is filled, the file is closed and
a new file is opened with the next higher version number.
- MULTIPLE - If this parameter is set to 1, a new version of the file of
logged data is created each midnight.
- SNS_LIMIT - The maximum number of entries which may be put on the queue
of inputs received over the network.
Current Record Numbers
The file of collected data is considered to consist of six sections, one
for each of the six data acquisition lists. Each record has a key which
specifies the number of the list and a record number for this list.
The data collection process periodically writes to disk the current record
number for each data acquisition list. The logical name DLG_BLOCKS_`node'
specifies the file containing the current record numbers. The format of the
file is binary with only the first six words of the file being used.
Device Names and Properties
The logical name DLG_LIST`n'_`node' specifies a file containing the device
names and properties which are to be read. `N' is the number of the
corresponding data acquisition list (1 to 6) and
`Node' is the name of the VAX node on which the collection process is
executing. A device file is an ASCII file which is created and modified by the
data logging editing process. A record in one of these files consists of the
name of the device followed by a character fields for each of the
reading, setting, and status properties as read from left to right.
A period in one of these character fields indicates the property does
not exist. An underscore indicates the property exists but is not to be
logged. An asterisk indicates the property is to be logged. Any additional
information a record may contain is not used by the collection process.
Output Files
The two primary data acquisition output files contain (1) the collected data
and (2) the current record numbers.
The logical name DLG_COLLECTED_`node' specifies the file containing the
data read by the data collection process, where `node' is the name of the VAX
node on which the process is executing.
The logical name DLG_BLOCKS_`node'
specifies the file into which the current record numbers of all the data
acquisition lists are periodically written.
Each time the collection process restarts
a data acquisition list, it writes a text file whose name has the format
DLG_LIST`n'_`node'.LST, where `n' is the number of the list and `node' is the
name of the VAX node on which the process is executing. A record in this file
contains the name of the device, an indication of the property, the name of
the node, the number of the list, the number of the item in the list, and the
time at which the list was restarted. The property is indicated by a T for
status, an E for setting, and a blank for reading. This same information
along with the FTD of the list is
appended to the end of a history file maintained by the collection process.
The format of the name of the history file is `node'.HIS.
General diagnostic information is written to a file whose name has the format
LOGGING_`node'.OUT. Severe error messages are output to a file whose name has
the format LOGGING_`node'.ERR.
Logical Names
- DLG_LOGGERS - Specifies all the VAX nodes on which data
collection processes are executing and which are accessible to the requesting
user. This logical is used by the data logging extraction process and the
data logging editing process to know what logging files may be accessed.
- DLG_NET_OBJ_`node' - For the purpose of enabling network communication,
the data collection
process declares itself to be a network object. The process translates this
logical to get its network object name.
- DLG_NODE_`node' - Specifies where the default data
collection process to be associated with `node' is executing.
- DLG_BLOCKS_`node' - current record numbers of the lists
- DLG_COLLECTED_`node' - collected data
- DLG_PARAMS_`node' - FTD and size specifications
- DLG_LIST`n'_`node' - device and property names
- DLG_SERVER_`node' - Specifies the node on which the associated file
server process is executing. This logical name is only used if the
NETWORK_OUTPUT parameter was set to one.
- DLG_SRV_OBJ_`node' - Specifies the network object name of the
associated file server process. This logical name is only used if the
NETWORK_OUTPUT parameter was set to one.
Network Command Input
As part of its initialization, the data logging collection process declares
itself to be a network object so that it may receive commands over the
network. The command most commonly received is RESTART of a specific data
acquisition list. This command is sent by the data logging editing process
upon request of the user after having modified the devices to be read by the
data acquisition list. Other commands exist but are for system and diagnostic
use.
- Restart # (R) - restart the identified data acquisition list. A number
of 0 to 6 may be specified. If 0 is used, all the lists are restarted.
If the list is executing, it is first canceled. The associated disk file
is input, the necessary data structures are built, and then the data
acquisition list is started.
- Stop # (S) - stop the identified data acquisition list. A number
of 0 to 6 may be specified. If 0 is used, all the lists are stopped.
If the list is executing, it is canceled.
- Flush # (F) - queue to be output to disk all the data buffers currently
allocated for the devices associated with the specified data acquisition
list.
- Parameters (P) - read the file of parameters associated with the
specified
data acquisition list. This command enables system management personnel to
modify a parameter file using a text editor and then have the data collection
process read the updated file without having to restart the process. However,
any change in a data acquisition rate will not take effect until the next time
the list is restarted.
- Diagnostic statistics (D) - write to the diagnostic disk file all
performance
statistics. Also return this information over the network to the requesting
process.
- Exit (E) - cancel all data acquisition lists, flush all data buffers to
disk, and then exit.
- Quit (Q) - exit immediately without trying to do any cleanup.
- New output file (N) - close the logging file into which the collected data
is being written and create a new output file.
Security, Privacy, Legal
rwest@fsus04.fnal.gov